
Data acquisition
In order to find matches between records, FuzzyPhoto needs data that is consistent and as complete as possible and free from errors. The first step was to review partners’ collections to agree which records to import. The seed records of Photographs Exhibited in Britain 1839-1865 (peib.dmu.ac.uk) and Exhibitions of the Royal Photographic Society 1870-1915 (erps.dmu.ac.uk) provided a target date range and additionally the title, person and process fields were identified as the basis for identifying record matches. However the project accepted records of any period so long as it included the range 1839-1915 and any fields so long as they included title, person and process, in order to minimize the work required by partners to export their data records.
The next step was to formally agree the conditions under which data would be shared. A Memorandum of Agreement was signed by all but one of the partners. The latter required a formal legally binding contract, which took rather longer to agree, particularly since it had to be translated into the language of the partner.
Partner records were acquired largely by file transfer and checked for consistency, accuracy, duplication and completeness. Considerable variation in the quality and structure of the data from different sources required extensive data preparation to import it all into the data warehouse with a common metadata schema, precluding the use of a batch loader as originally planned (batch loader).
Finding matches
Four fields were used to identify potential record matches within the acquired data: person, date, process and title. Data in the “person” field might refer the photographer or the exhibitor or the owner and thus may vary between different collections depending on what is known about the photograph in that collection. Also the way in which name information is recorded varies, with firstname, intials, family name, titles presented in different orders, with varying degrees of contraction and sometimes presented in separate fields and sometimes all together in a single field, or not in a field at all.
“Date” might be the date on which the photograph was originally shot, the date on which a particular print was made, or exhibited, or some other date such as the date of acquisition by the owner/collection. Dates also have varying degrees of precision such as “circa”, “late 19th century”, “1890’s” etc. and might be represented in numbers, words and in different day/month/year order. In one collection alone there were 20 different ways of representing date information.
“Process” refers to the process used to create the photograph, bearing in mind that most photographic prints entail a negative as well as a positive process and that it is possible to print a positive using a variety of different processes from the same negative. Some, but not all of the records included process information.
“Title” is the name of the photograph, or the description, if it has one. While some titles run to several paragraphs, most are very short, containing only 5.4 usable words each on average. Such a small amount of text makes it difficult to find matches between titles. To the project has increased the chances of finding matches by semantically expanding the number of terms that can be searched for, using WordNet. For example, a title containing the word “flower” is judged similar to one containing the word “daffodil”. The more words there are in a pair of titles that are similar, the closer the match between the titles is judged to be.
The overall similarity between titles is estimated using a combination of the four individual similarity metrics of person, date, process and title. For details of how these metrics work, see report on this link (click here).
Displaying links
Potential matches between records are stored as links in a MySQL database and exported to the partners. Each partner Web site has a small piece of code embedded in it such that when a visitor to that site drills down to the level of an individual photographic record a list of possible links appears on that Web page. Visitors can choose which links, if any, they wish to follow back to the originating partners’ collections.
Technical Infrastructure
A MySQL server cluster is the main data repository for the FuzzyPhoto project. The data comprise meta-data relating to historical photographs. The cluster also serves to assist in the processing of links between these collections. The structure of the cluster maintains data isolation from external access along with allowing continued, sustained expansion of core structure. Figure 1 shows how the cluster relates to other elements within the process. The main output from the cluster is a links database. Users can access this database via a web server. The links database is periodically updated from the cluster through a defined link.
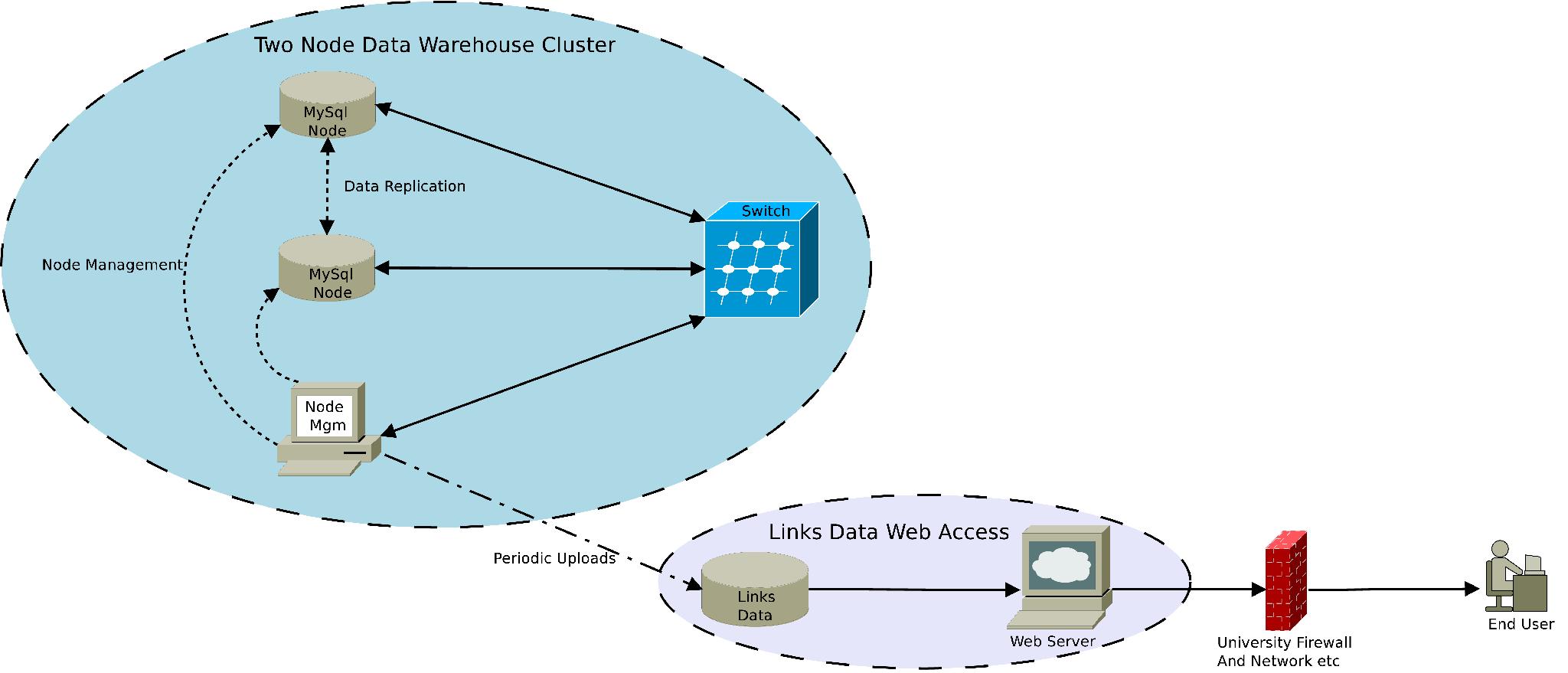
For more details of the server cluster see MySQL Cluster Documentation.